الگوریتم YOLO از صفر تا پیشرفته: تشخیص اشیای بلادرنگ با نگاهی عمیق به نسخههای v1 تا v8

در سالهای اخیر، حوزهٔ بینایی ماشین با پیشرفتهای شگفتانگیزی در یادگیری عمیق روبهرو شده است. در میان دستاوردهای متعدد، خانوادهٔ الگوریتمهای YOLO (You Only Look Once) بهخاطر ترکیب منحصربهفرد سرعت و دقت، برجسته شدهاند. برخلاف…
در سالهای اخیر، حوزهٔ بینایی ماشین با پیشرفتهای شگفتانگیزی در یادگیری عمیق روبهرو شده است. در میان دستاوردهای متعدد، خانوادهٔ الگوریتمهای YOLO (You Only Look Once) بهخاطر ترکیب منحصربهفرد سرعت و دقت، برجسته شدهاند. برخلاف تشخیصهای سنتی دو مرحلهای که ابتدا پیشنهاد نواحی (Region Proposals) و سپس طبقهبندی و اصلاح جعبهها را انجام میدادند (مانند سری R-CNN)، YOLO تشخیص اشیا را به یک مسئلهٔ رگرسیون یکباره تبدیل میکند و کل تصویر را در یک گذار به شبکهٔ عصبی میفرستد. این طراحی به عملکرد بلادرنگ (Real-Time) منجر میشود و آن را برای کاربردهایی مانند خودروهای خودران، رباتیک، پهپادها و تحلیل ویدئوی زنده بسیار مناسب میسازد.در این پست بلاگ بهطور جامع به الگوریتم YOLO میپردازیم: از نسخهٔ اولیه (v1) تا جدیدترین حالت (v8)، نوآوریهای معماری، استراتژیهای آموزش، ویژگیهای عملکردی، نکات پیادهسازی، کاربردهای دنیای واقعی، محدودیتها و جهتهای آیندهٔ تحقیق در تشخیص اشیا.
پیشزمینه: از پیشنهاد ناحیه تا تشخیص تکمرحلهای
پیش از الگوریتم YOLO، تشخیص اشیا معمولاً به صورت دو مرحلهای انجام میشد:
-
پیشنهاد ناحیه (Region Proposal): روشهایی مانند Selective Search جعبههای نامزد (RoIs) را تولید میکردند که احتمال داشت حاوی شیء باشند.
-
طبقهبندی و اصلاح: هر RoI به یک شبکهٔ کانولوشنی فرستاده میشد تا شیء را طبقهبندی کرده و مختصات جعبه را تصحیح کند.
مثالها شامل R-CNN (۲۰۱۴)، Fast R-CNN (۲۰۱۵) و Faster R-CNN (۲۰۱۵) هستند. با اینکه این روشها دقت بالایی داشتند، اما بهدلیل پردازش هر ناحیه بهصورت جداگانه کند بودند.
برای پاسخ به این مشکل، روشهایی مانند SSD (Single Shot Multibox Detector) و YOLOv1 تشخیص را به یک مسئلهٔ رگرسیون واحد تبدیل کردند و بهطور مستقیم کلاسها و موقعیت جعبهها را از تصویر کامل پیشبینی کردند. این کار با حذف مرحلهٔ پیشنهاد ناحیه، سرعت را به میزان چشمگیری افزایش داد، در حالی که افت دقت نسبتاً کمی به همراه داشت.

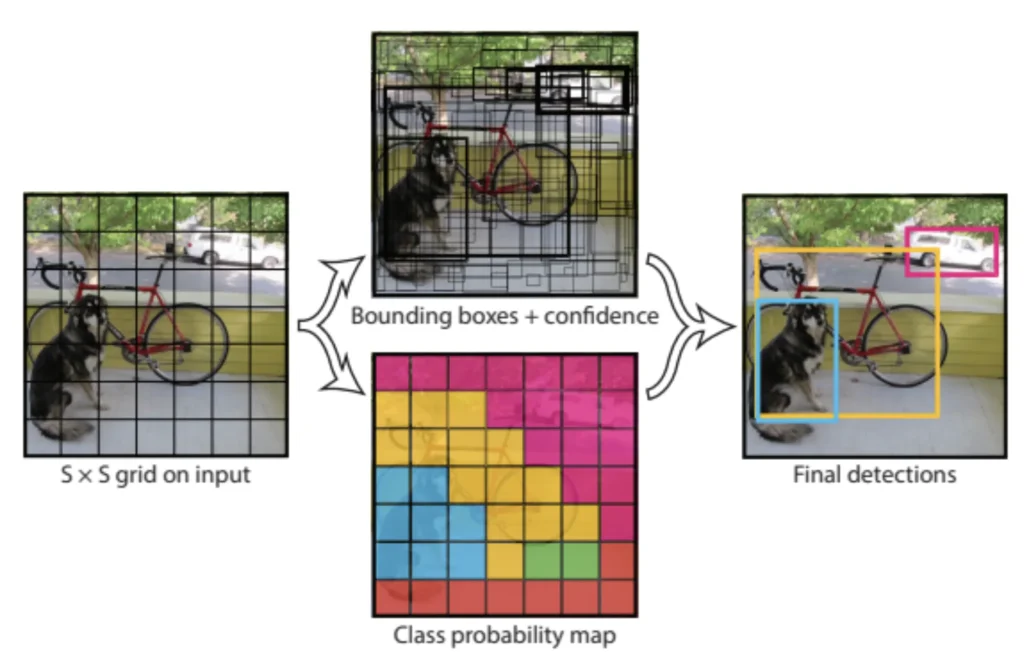
YOLOv1: تولد تشخیص اشیای بلادرنگ
منتشرشده در ۲۰۱۶ توسط جوزف ردمون و همکاران، YOLOv1 رویکرد کاملاً جدیدی ارائه داد:
-
تقسیمبندی شبکه (Grid): تصویر ورودی به یک شبکهٔ S×S (معمولاً ۷×۷) تقسیم میشود.
-
پیشبینیها در هر سلول: هر سلول شبکه B جعبهٔ محدودکننده (مختصات و امتیاز اعتماد) و C احتمال کلاس را پیشبینی میکند.
-
تابع خطای یکپارچه: خطاهای مکانیابی، اعتماد و طبقهبندی را بهطور همزمان جبران میکند.
مزایا
-
سرعت: تنها یک گذار شبکه کل تصویر را پردازش میکند و به سرعت ۴۵ فریم بر ثانیه (FPS) روی GPU Titan X دست مییابد.
-
تفکر کلنگر: مدل با دسترسی به بافت کامل تصویر، خطاهای مثبت کاذب در پسزمینه را کاهش میدهد.
محدودیتها
-
شبکهٔ درشت: شبکهٔ ثابت، تعداد کمی شیء را در هر سلول میتواند تشخیص دهد و عملکرد ضعیفی در اشیای کوچک و متراکم دارد.
-
خطاهای مکانیابی: پیشبینی مستقیم جعبهها بدون جعبههای لنگر (Anchor Boxes) دقت کمتری دارد.
با وجود این ضعفها (mAP حدود ۵۷.۹٪ روی Pascal VOC)، YOLOv1 امکان تشخیص یکباره را اثبات کرد و جامعهٔ بینایی ماشین را به سمت مدلهای بلادرنگ هدایت نمود.
YOLOv2 و YOLOv3: تلفیق دقت و سرعت
YOLOv2 (YOLO9000)
برای رفع ضعفهای YOLOv1، YOLOv2 (۲۰۱۶) چندین بهبود ارائه داد:
-
Batch Normalization بر روی تمام لایههای کانولوشنی برای بهبود همگرایی و تنظیم مدل.
-
پیشآموزش با وضوح بالا (448×448) برای یادگیری بهتر ویژگیها.
-
جعبههای لنگری (Anchor Boxes) از Faster R-CNN قرض گرفته شد و با خوشهبندی k-means بهینهسازی شد.
-
خوشههای ابعاد (Dimension Clusters) برای مقداردهی اولیه بهتر لنگرها.
-
پیشبینی مستقیم مکان به صورت آفست نسبت به لنگرها برای پایداری بیشتر در آموزش.
-
آموزش چند-وضوحی: تغییر تصادفی اندازهٔ ورودی بین ۳۲۰×۳۲۰ تا ۶۰۸×۶۰۸ هر چند دسته.
این تغییرات mAP را روی VOC به ۷۸.۶٪ رساند و همچنان سرعت بالای ۴۰+ FPS حفظ شد. YOLO9000 با آموزش همزمان روی دادههای تشخیص COCO و برچسبهای طبقهبندی ImageNet، قادر به تشخیص بیش از ۹۰۰۰ کلاس شد.
YOLOv3
در ۲۰۱۸، YOLOv3 پیشرفتهای بیشتری داشت:
-
معماری شبکهٔ پشتی (Backbone): معرفی Darknet-53 با ۵۳ لایه و اتصالات باقیمانده (Residual Connections) که تعادل خوبی بین دقت و سرعت ارائه میدهد.
-
پیشبینی چندمقیاسی (FPN-Style): تشخیص در سه مقیاس (۸۲×۸۲، ۴۲×۴۲، ۲۱×۲۱) برای بهبود شناسایی اشیای کوچک، متوسط و بزرگ.
-
طبقهبند لجستیک مستقل: جایگزینی Softmax با چندین طبقهبند مستقل Logistic برای پشتیبانی از چند-برچسب.
-
تابع خطای بهبود یافته: استفاده از Binary Cross-Entropy برای طبقهبندی و مجموع مربعات خطا برای موقعیت و اعتماد.
YOLOv3 mAP حدود ۵۷.۹٪ روی COCO (IoU=0.5) و سرعت ۲۰–۳۰ FPS را ارائه میدهد که آن را برای کاربردهای عملی محبوب کرده است.
YOLOv4 تا YOLOv8: پیشبرد مرزها
YOLOv4 (۲۰۲۰)
الکسی بوچکوفسکی و همکاران با ترکیب «کیسهٔ ترفندها» (Bag of Freebies) و «کیسهٔ ویژهسازیها» (Bag of Specials) نسخهٔ YOLOv4 را معرفی کردند:
-
CSPDarknet53 Backbone: شبکهٔ Cross-Stage Partial برای جریان بهتر گرادیان.
-
افزایش دادهٔ Mosaic و MixUp برای تنوع بیشتر.
-
Self-Adversarial Training (SAT) و DropBlock برای تنظیم منظمتر مدل.
-
CIoU Loss برای همگرایی سریعتر و دقیقتر.
-
SAM (Spatial Attention Module) و PAN (Path Aggregation Network) برای ادغام بهتر ویژگیها.
این اصلاحات mAP را روی COCO به ۴۳.۵٪ در ۶۵ FPS برای مدل “YOLOv4-CSP” رساند که پیشرفت چشمگیری نسبت به YOLOv3 داشت.
YOLOv5 (۲۰۲۰–تاکنون)
اگرچه نسخهای رسمی از نویسندگان اصلی نبود، YOLOv5 توسط Ultralytics محبوب شد:
-
پیادهسازی PyTorch: کد ساده، مستندات فراوان و توسعهٔ فعال.
-
یادگیری خودکار لنگرها: محاسبهٔ اتوماتیک بهترین لنگرها برای دادهٔ جدید.
-
متنوعسازی مدلها: YOLOv5s (کوچک)، m (متوسط)، l (بزرگ)، x (خیلی بزرگ).
-
روند آموزش بهبود یافته: تکامل خودکار ابرپارامترها و اسکریپتهای افزایش داده.
مدلهای YOLOv5 mAP حدود ۵۰–۵۵٪ روی COCO را با سرعت بیش از ۱۴۰ FPS (برای کوچکترین نسخه) ارائه میدهند، مناسب استقرار در لبهٔ شبکه.
YOLOv6 و YOLOv7
گروههای تحقیقاتی صنعتی و مشارکتکنندگان جامعه بهروزرسانیهایی عرضه کردهاند:
-
YOLOv6: بهینهسازی تأخیر برای موبایل و FPGA، و افزودن ماژولهای شبه-ترنسفورمر.
-
YOLOv7: معرفی ماژولهای قابل آموزش E-ELAN (Extended Efficient Layer Aggregation Network)، mAP تا ۵۶.۸٪ روی COCO با سرعت ۳۰+ FPS. همچنین مجموعهای از ماژولهای «پلاگانپلی» برای پژوهشگران دارد.
YOLOv8 (۲۰۲۳)
Ultralytics YOLOv8 را منتشر کرد که ویژگیهای زیر را دارد:
-
همهکاره: تشخیص، تقسیمبندی و طبقهبندی در یک کدبیس.
-
بدون لنگر (Anchor-Free) بهعنوان حالت پیشفرض برای سادگی و پایداری آموزش.
-
C2f Backbone سبک و پرکارایی برای استخراج ویژگی.
-
ابزارهای استقرار پیشرفته: پشتیبانی بومی از TensorRT، OpenVINO، CoreML و ONNX برای تنوع سختافزاری.
YOLOv8 mAP تا ۶۰٪ روی COCO را با سرعت بیش از ۱۲۰ FPS روی GPU ارائه میدهد و استانداردهای جدیدی در تشخیص بلادرنگ ایجاد کرده است.
تفسیر معماری
با وجود تفاوتهای نسخهها، ساختار کلی YOLO شامل سه قسمت است:
-
Backbone (شبکه پشتی):
استخراج نقشههای ویژگی سلسلهمراتبی از تصویر ورودی.-
نسخههای اولیه از Darknet استفاده میکردند؛ نسخههای جدیدتر از CSP و C2f بهره میبرند.
-
-
Neck (گردن):
ادغام ویژگیهای چندمقیاسی.-
از FPN، PAN یا ماژولهای اختصاصی برای ترکیب ویژگیهای سطح پایین و بالا استفاده میکند.
-
-
Head (سر):
پیشبینی جعبهها و احتمال کلاسها.-
مبتنی بر لنگر (v2–v7) یا بدون لنگر (v8).
-
سرهای چندمقیاسی برای تشخیص اشیای مختلف.
-
عملیات کلیدی شامل کانولوشن، نرمالسازی دستهای یا لایهای، توابع فعالسازی (ReLU، Leaky ReLU، Mish، SiLU) و نمونهبرداری فضایی (کاهش/افزایش وضوح) هستند.
نکات مهم در آموزش YOLO
برای آموزش مؤثر یک مدل YOLO، مراحل زیر توصیه میشود:
-
آمادهسازی داده:
-
برچسبگذاری تصاویر در فرمت YOLO (
class x_center y_center width heightنرمالشده). -
استفاده از مجموعههای عمومی مانند COCO، Pascal VOC یا دادههای سفارشی.
-
-
افزایش داده:
-
Mosaic: ترکیب چهار تصویر در یک تصویر برای بهبود تشخیص اشیای کوچک.
-
MixUp: ترکیب تصاویر و برچسبها برای منظمسازی.
-
تغییر رنگ، چرخش، مقیاسدهی برای افزایش مقاومت.
-
-
ابرپارامترها:
-
Batch Size: اندازه بزرگتر ناپایداری آموزش را کاهش میدهد؛ محدود به حافظهٔ GPU.
-
نرخ یادگیری: از گرمکردن تدریجی و زمانبندی Cosine Annealing برای همگرایی نرمتر استفاده کنید.
-
Weight Decay: جلوگیری از بیشبرازش، معمولاً بین ۰.۰۰۰۵–۰.۰۰۰۱.
-
-
محاسبه لنگرها (Anchor-Based):
-
اجرای خوشهبندی k-means روی ابعاد جعبهها برای یافتن بهترین لنگرها.
-
-
تابعهای خطا:
-
خطای مکانیابی: MSE (v1–v3)، CIoU/GIoU (v4+).
-
خطای اعتماد: تعادل میان نمونههای دارای شیء و بدون شیء.
-
خطای طبقهبندی: BCE یا Cross-Entropy.
-
-
اعتبارسنجی و توقف زودهنگام:
-
نظارت بر mAP@0.5 و mAP@[0.5:0.95] روی مجموعهٔ اعتبارسنجی.
-
استفاده از توقف زودهنگام برای جلوگیری از بیشبرازش.
-
مخازن Ultralytics برای YOLOv5–v8 شامل اسکریپتهای کامل آموزش، فایلهای پیکربندی YAML و پیشتنظیمهای ابرپارامتر است که آزمایش را ساده میکنند.
استنتاج و استقرار
یکی از ویژگیهای برجستهٔ الگوریتم YOLO انعطافپذیری در استقرار است:
-
حالتهای دقت: FP32 برای دقت بیشتر؛ FP16 یا کمیتسازی INT8 برای افزایش Throughput روی هستههای تانسور NVIDIA یا دستگاههای لبه.
-
قالبهای خروجی: ONNX، TensorRT، CoreML، TFLite یا OpenVINO برای اجرا روی GPU، CPU، موبایل یا شتابدهندههای تخصصی.
-
پردازش دستهای در مقابل جریان: برای ویدئوی بلادرنگ فریمها را جداگانه پردازش کنید. برای تحلیل آفلاین میتوانید دستهای اجرا کنید.
-
پسپردازش:
-
NMS یا Soft-NMS برای فیلتر کردن جعبههای همپوشان.
-
آستانهٔ اعتماد (معمولاً ۰.۲۵–۰.۵) برای حذف جعبههای کماعتماد.
-
چارچوبهایی مانند NVIDIA DeepStream، OpenVINO Toolkit و TensorRT خطوط لولهٔ انتها به انتها را برای استقرار مدلهای YOLO فراهم میکنند.
کاربردهای دنیای واقعی
سرعت و دقت الگوریتم YOLO آن را برای موارد زیر محبوب کرده است:
-
خودروهای خودران:
تشخیص بلادرنگ عابران، خودروها، تابلوهای ترافیکی و موانع. -
نظارت با پهپاد:
نسخههای سبک الگوریتم YOLO روی GPUهای تعبیهشده اجرا میشوند تا حیاتوحش، خرابی زیرساخت یا ورود غیرمجاز را شناسایی کنند. -
تحلیل خردهفروشی:
دوربینهای فروشگاهی برای شمارش مشتریان، تشخیص صف و بررسی موجودی کالا. -
بهداشت و درمان:
تحلیل تصاویر پزشکی مانند تشخیص تومور در رادیوگرافی یا تقسیمبندی در بافتشناسی. -
اتوماسیون صنعتی:
سیستمهای رباتیک Pick-and-Place برای تشخیص قطعات روی نوار نقاله با تأخیر میلیثانیهای. -
واقعیت افزوده (AR):
درک صحنهٔ بلادرنگ برای جایگذاری محتوا در بازیها یا آموزشهای صنعتی.
چالشها و محدودیتها
با وجود تحولآفرینی، الگوریتم YOLO با چالشهایی روبهرو است:
-
تشخیص اشیای کوچک:
اشیای بسیار کوچک ممکن است در نقشههای ویژگی گم شوند، اگرچه سرهای چندمقیاسی کمک میکنند. -
پوشیدگی و صحنههای شلوغ:
اشیای همپوشان میتوانند NMS و رگرسیون جعبه را سخت کنند. -
جابجایی حوزه (Domain Shift):
مدلهای آموزشدیده در یک محیط ممکن است در شرایط متفاوت (مثلاً شب یا تصاویر حرارتی) دچار افت شوند. -
محدودیتهای منابع:
حتی نسخههای سبک الگوریتم YOLO برای زمان واقعی نیاز به GPU یا شتابدهنده دارند؛ اجرای صرفاً CPU ممکن است کند باشد. -
قابلیت تبیینپذیری:
مانند بسیاری از مدلهای عمیق، الگوریتم YOLO به صورت «جعبهٔ سیاه» عمل میکند و تبیین خطاها و تعصبات دشوار است.
جهتهای آینده
چشمانداز تشخیص اشیا همچنان در حال تحول است. روندهای نویدبخش عبارتاند از:
-
ترنسفورمرهای بینایی (ViTs) برای تشخیص:
روشهایی مانند DETR تشخیص انتها-به-انتها را بدون جعبههای لنگر یا NMS ارائه میدهند. -
یادگیری خودنظارتی و نیمهنظارتی:
کاهش نیاز به دادههای برچسبخورده با یادگیری کانtrastive یا برچسبسازی خودکار. -
یادگیری مستمر و مادامالعمر:
امکان یادگیری کلاسها و محیطهای جدید بدون فراموشی فاجعهبار. -
هوش لبه و TinyML:
فشردهسازی بیشتر مدلها برای اجرا روی میکروکنترلرها و دستگاههای IoT. -
تشخیص شی سهبعدی:
ترکیب اصول YOLO با دادههای LiDAR و عمق برای برآورد جعبههای سهبعدی. -
تشخیص چندوجهی:
ترکیب بینایی با صدا، رادار یا متن برای درک غنیتر صحنه.
با پیشرفت تحقیقات در این زمینهها، نسخههای آیندهٔ YOLO احتمالاً مکانیسمهای توجه، ترنسفورمرهای بینایی و پیشآموزشهای خودنظارتی را در خود جای خواهند داد تا هم سرعت و هم دقت را افزایش دهند.
نتیجهگیری
از زمان ظهور در ۲۰۱۶، YOLO تعریف جدیدی از تشخیص اشیای بلادرنگ ارائه داده است. با یکپارچهسازی پیشنهاد ناحیه، طبقهبندی و مکانیابی در یک شبکهٔ انتها-به-انتها، YOLO سرعتی بینظیر را بدون افت قابل توجه در دقت فراهم میکند. از نسخهٔ v1 تا v8، نوآوریهای معماری، تابع خطا، افزایش داده و ابزارهای استقرار، همواره مرزها را جابهجا کردهاند.
چه در حال ساخت پهپادهای خودران، سیستمهای خردهفروشی هوشمند یا خطوط لولهٔ تصویربرداری پزشکی باشید، YOLO راهحلی همهجانبه ارائه میدهد. با درک عمیق این پست، اکنون میتوانید نسخهٔ مناسب YOLO را انتخاب، دادهها را آماده، ابرپارامترها را تنظیم و مدلها را در مقیاس عملیاتی استقرار دهید. با ادامهٔ پیشرفت حوزه—از ترنسفورمرها تا هوش لبه و یادگیری خودنظارتی—مطمئن باشید سیستم تشخیص شما در خط مقدم فناوری باقی میماند.
سفر خود را با YOLO امروز آغاز کنید و قدرت بینایی بلادرنگ را آزاد نمایید!





